
News|Articles|November 8, 2024 (Updated: November 19, 2025)
Laser Induced Breakdown Spectroscopy Combined with a Tuned Back Propagation Algorithm for Oil Crop Straw Combustion Smoke Detection and Traceability
Listen
0:00 / 0:00
Key Takeaways
- LIBS and BP neural network system effectively analyzes and traces crop burning smoke, identifying heavy metals like Fe, Mn, Sr, and Ba.
- The BP model, optimized for hyperparameters, achieved an 86.67% accuracy in tracing the origins of combustion smoke from rape seed, corn, and sesame straws.
Advertisement
In this paper, a system based on laser induced breakdown spectroscopy (LIBS) and back propagation (BP) method was developed for the composition and traceability analysis of crop burning smoke. Three types of soil crops (rape seed, corn, sesame) straw were researched and the spectra was monitored using this new developed system. The analysis of crop straws burning smoke spectra shows that there are heavy metals (Fe, Mn, Sr and Ba) in the smoke. To trace the smoke generated by crops burning, a BP neural network (NN) method was studied. The BP model was trained and tested on the normalized spectra data of crops burning smoke. The relevant hyperparameters of BP model were tuned to gain the best test results. The total prediction accuracy of the tuned BP model for the combustion smoke of three crops could reach 86.67%. The results show that the system based on LIBS technique and BP algorithm has the potential to improve rapid in-situ detection of air quality and traceability of combustion smoke.
Crop straw is one of the most abundant biomass resources in the world. At present, the frontier research on straw mainly focuses on improving the utilization rate of straw. For example, rape straw is used as feedstock to prepare the double functional carbon-based ZnO (RS/ZnO) using ZnCl2 as activation agent by one-pot method for dye wastewater removal (1). To reduce environmental problems caused by combustion of fossil energy and accumulation of crop straw, Liu W. and others (2) produced high-yield hydrogen with cheap straw as raw materials. However, most straws are randomly stacked or burned in the open air (3). As far as we know, there are few studies related to the traceability of straw burning, because the online detection and traceability of straw burning is challenging.
As a high-sensitivity optical detection technology, LIBS generates high-temperature plasma and plasma emission lines by high-energy pulsed laser radiation of target samples (4). The analysis speed is fast, the sample demand is small, and the requirements for the size, shape and physical properties of the sample are not strict. LIBS technology has achieved good application results in land fertility monitoring, soil heavy metal detection, water quality detection, food safety detection, and discrimination in rare woods, and medicinal materials (5–8). These unique advantages are unmatched by traditional spectroscopy. Ye Y. P. and others (9) used LIBS and a random forest algorithm to monitor and trace straw burning flue gas online, and obtained a high quality smoke identification. LIBS still has some shortcomings in the online detection of straw burning smoke components. For example, the smoke generated by straw combustion is variable in concentration strength, which has a certain impact on the experimental results. To solve the problem of smoke detection and traceability caused by crop straw combustion, this paper proposes an experimental system based on LIBS and a BP neural network.
A BP neural network is a multi-layer feedforward neural network trained by error back propagation algorithm. It is one of the most widely used artificial neural network (ANN) models. BP algorithm is a commonly used neural network training algorithm, which can deal with nonlinear problems. It has strong adaptability and generalization ability, and is suitable for various pattern recognition and prediction problems. There have been many research reports on the application of LIBS technology combined with the BP algorithm (10,11). In this paper, LIBS technology combined with a tunned BP algorithm was used to realize the detection and traceability of crop straw burning smoke. In short, LIBS technology was used to obtain the full emission spectrum information of crops straw burning smoke, and the main elements composition of smoke were obtained through spectral analysis. The BP algorithm was to trace the stalk burning smoke.
Experiment
Sample
Crops generally include food crops, cash crops and green manure crops. In this study, oil crops in economic crops were selected as experimental research objects. Oil crops also include rape, peanut, sesame, sunflower, corn, and so forth. In this paper, three kinds of crops (rape, corn, sesame) straw were selected for incineration smoke detection. These samples not only have a wide range of sources, but also have a wide variety of smoke generated during the combustion process, which can fully reflect the smoke composition and emission characteristics generated during the crop straw combustion. All straws are from East Asia. Before conducting the experiment, these samples are treated, such as removing impurities (soil or rocks), drying, and so forth.
Experimental System
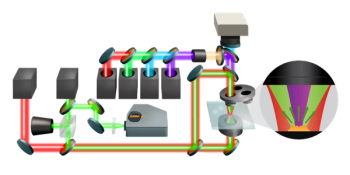
The LIBS experimental system for detecting crop straw combustion smoke is shown in Figure 1. The LIBS experimental system is composed of the laser generation system, signal detection system, spectral analysis system. The laser generation system contains a laser, a plane reflector, and a convex lens. The signal detection system contains a delay, a 4-channel spectrometer, and a signal collector. The spectral analysis system is a computer. The laser wavelength is 1064 nm, the laser spot size is 7 ± 0.1 mm, the spot irradiance can reach 5.3 × 107 W/cm2, the frequency is 10 Hz, the single pulse duration is 10 ns, and the pulse energy is 250 mJ. The focal length of the convex lens is 6 cm. The spectral range of the spectrometer is about 210–890 nm, the spectral resolution is 0.1 nm, and the integration time of the spectrometer is set to be 2 ms. In order to reduce background noise and obtain better spectral resolution, a delay of 2.5 μs is added between the spectrometer and the laser.
Spectral Analysis of Oil Crops Straw Combustion Smoke
With reference to the database information published by the U.S. National Institute of Standards and Technology (NIST) (12), element calibration and calibration were carried out on the obtained spectral data. Here, the smoke spectrum of burning corn straw samples was analyzed. For the spectrum of combustion smoke of other samples, some bands are selected for comparative discussion. Figure 2 shows the spectra of four bands, covering the full emission spectrum range from 210 nm to 890 nm. The spectral lines of different elements such as C, Fe, Mg, Mn, Al, Ca, Si, K, H, Na, Ba, Sr, N, O can be clearly observed in Figure 2. Fe, Mn, Sr and Ba are heavy metal elements, and their spectral characteristic peaks are less pronounced, indicating that these heavy metal elements are of lesser concentration in the sample. In Figure 2b, CN bands of Δv = 1 and Δv = 0 are also observed, which are mainly formed by C in rape and N in air. The spectral lines in Figure 2d are the emission spectra of N and O, both of which come from the air.
To compare the emission spectra of three kinds of crop burning smoke, the spectra in the wavelength range of 450 nm–700 nm are given, as shown in Figure 3. It can be seen from Figure 3 that the spectral lines of the three crops burning smoke are similar. They all contain the spectral lines of Ba, Ca, Mg, Na, H, and other elements. However, due to the different excitation energy each crop receives, the spectral lines are slightly different, and the spectral intensity of rape stem combustion is the largest. Therefore, the spectral lines excited in Figure 3a are also the most. There are 20 spectral lines of element (Ca). The spectral lines of the element (Sr) are also excited. Figure 3b shows that the laser excitation energy is the smallest. Only 8 spectral lines of element (Ca) were observed and marked, and no spectral line of element (Sr) was found. The difference in the intensity of the smoke spectral lines of the three crops in Figure 3 is not due to the different laser energy used, but due to the different energy received by the smoke during the manual experimental operation. It is also because different crop combustion smoke has different energy spectrum lines, so intelligent algorithms can be used to trace the smoke. All element spectral lines (wavelengths) with large intensity differences can be selected as characteristic spectra.
Spectral Data Pre-Processing
One thousand (1000) different spectra [wavelength (λ), emission intensity values (intensity)] of each sample were recorded. There were 8192 spectral intensity points. First, the Z-score normalization (zero-mean normalization) method was used to standardize the raw data. The processed data conforms to the standard normal distribution, and the transformation function is shown in equation 1.
Where x is the raw data, x* is normalized data, μ is the mean of all sample data, and δ is the standard deviation of all sample data. It can improve data comparability, and weakens data interpretability.
To reduce the size of the raw data, it needs to be filtered. After eliminating incorrect and abnormal values, 100 groups of samples were randomly selected from the correct spectral data of each straw smoke for classification and traceability. A total of 300 groups of samples were obtained. For each full emission spectra, the spectrometer measured a total of 8192 intensity points. It is obviously inappropriate to use 8192 intensity points as the basis for straw classification and traceability, and it can lead to the complexity of subsequent machine learning (ML) models. Therefore, by comparing the standard deviation of each spectral line, 72 characteristic spectral lines with large margin were selected as the original variables. According to the analysis results in section 2.3, there are many emission lines that can be used as the features and they are easy to be found. The spectra (emission intensity) of C, CN, Si, Mn, Al, Fe, Mg, Ca, N and O can be used as characteristic spectral lines, as shown in Table I.
However, these 72 variables have some problems such as high dimensionality, and some variables may express repetitive information.
The Establishment of BP Model and the Assessment of Traceability Results
BP Model
The BP neural network can capture highly complex data relationships and generate accurate classification or regression solutions for very large data sets. It can solve the problem of linear inseparability (13). The principle of the BP algorithm is to calculate the error between the output result and the actual value, and adjust the weights and thresholds of the input layer to the hidden layer and the hidden layer to the output layer according to the error result to obtain a relatively improved BP neural network prediction model. The error function isis the desired output of the network; y(m) is the real output, and m is the number of iterations. The weight adjustment of the hidden layer and the input layer is shown in equation 2.
Where ωij is the weighted value and η is the learning rate.
Neural networks are susceptible to overfitting when not enough training data is available, or when the data set is highly complex. During the training process, the error of the network on the training data gradually decreases, but the error on the verification set gradually increases. In order to avoid the over-fitting problem, the L2 regularization method (L2-norm) is usually used (14). The training parameters are manually controlled, and a regularization term about the weight is added to the error function e (n). The expression is shown in equation 3.
Where λ is the regularization parameter. By adjusting the value of λ, the influence of noise on data in BP model is reduced.
Hyperparameter Optimization
The prediction performance of the model depends on the setting of parameters. In this paper, the Bayesian optimizer is used to optimize the relevant parameters. By setting the range of parameters, the objective is to minimize the model error (mean square error, MSE). In addition, all data sets are split into 80/20% training set and test set. Through stratified sampling, the training set is randomly divided into five groups. Four groups are the training set, and one group is the test set. Iteration is performed within the set parameter range. Each optimization runs 50 iterations. The optimizer adjusts the hyperparameter value by evaluating the verification error at each iteration to obtain the optimal hyperparameter configuration (15,16). Table II gives the adjustable hyperparameters of BP model and the range of values investigated to determine the best model for each class. For the BP neural network model, a three-layer network structure is adopted. The input layer is determined by the number of characteristic spectra, and the tuning range is set to 3-72. The output layer is determined by the number of target categories of the model, and the range of hidden layers is 2-30. Other hyperparameters considered for optimization include activation function, iteration times, learning rate, and regularization constant. Among them, three kinds of activation functions are selected (Sigmoid, ReLU, tanh). The tuning range of the number of iterations is set to 100–2000 to adjust the time that the model must converge. The range of the learning rate is 0.1–0.0001, and the range of the regularization constant is [4.99e-5, 0.499]. The adjustment values of all the model hyperparameters used for the final predictive analysis are listed in the last column of Table II.
To evaluate the sensitivity and precision of BP model more clearly, MSE in the training progress and the prediction accuracy of the test samples were calculated. MSE is given by equation 4, where n, yi, and y^i refer to the total number of test points, the actual value, and the model predicted value, respectively.
A smaller MSE value indicates that the smaller training error of the model and the prediction accuracy is higher. However, if the model is overfitted, the prediction accuracy maybe smaller (17,18). Therefore, the prediction accuracy of the test points, that is, the recognition accuracy, is another important indicator to evaluate BP model in this paper. It is the ratio (η) of the number of correctly predicted points to the total number of test points. It is given by equation 5. Mcorrect is the number of correctly predicted samples. Ntest is the total number of test points.
Assessment of Traceability
Using the untuned hyperparameters (the third column) and the tuned hyperparameters shown in Table II (the last column), the straw combustion smoke traceability models were created and trained on the data set (80%), and then the test data (20% of the split) were passed through both models. The performance and recognition accuracy were evaluated according to the test results. The results are shown in Figure 4a and Figure 4b.
The MSE of tuned and untuned BP model are 0.0026926 and 0.048926 in Figure 4a, respectively. It indicates that the tuned BP model is better than the untuned BP. It also can be seen that the BP model without optimization converges faster. To ulteriorly evaluate performance of created BP model more clearly, the recognition accuracy of models on the test points were calculated. The classification confusion matrix shown in Figure 4b can well display the results of the test data classification operation and visualize the prediction accuracy. As the results of untuned BP model, among the 20 test samples of rape straw combustion smoke spectral, 15 test samples were predicted correctly, and 3 samples were predicted to be corn and 2 samples were predicted to be sesame. For the corn and Sesame test samples are similar. Figure 4b also gives the testing results of tuned BP model, among the 20 test samples of each straw combustion smoke spectra, the number of accurate prediction samples of rape, corn and sesame was 17, 19, and 16, respectively.
The calculated prediction accuracy of tuned BP model for crop straw burning is 86.67%, and the identification accuracy of each crop burning smoke is also above 80%. And for untuned BP model, the identification accuracy for combustion smoke tracing is 78.33%. The accuracy was smaller than the result of tuned BP model. It is opposite to the result given in Figure 4a. This result shows that the untuned BP model was over-fitted. The reason for over-fitting may be that the number of selected characteristic spectra is too large. Besides, the model is regularized by introducing a regularization constant (λ). The results showed that the tuned BP model overcomes the shortcomings of over-fitting and improved the generalization ability of the model after introducing the regularization constant and optimizing the number of characteristic spectra. The test results of the model show that LIBS combined with the BP algorithm can realize online detection and traceability of crop straw smoke.
Conclusion
In this paper, a system based on LIBS and tuned BP was developed to realize the online detection and traceability of straw burning. Three kinds of oil crop straw were selected as samples, taking rape straw as an example. After the spectral data were corrected and analyzed, the main elements in the rape straw combustion smoke spectrum were determined to be C, Fe, Mn, Mg, Al, Ca, Si, K, H, Na, Ba, Sr, N, and O. Among them, Fe, Mn, Ba and Sr are heavy metals. The created BP model was used to trace the source of three kinds of straw burning smoke. The relevant hyperparameters of the models were tuned to gain the best test results. The identification accuracy of tuned BP model for combustion smoke tracing is 86.67%. Comparing the untuned BP model, the prediction accuracy is obviously improved. The results indicates that it is feasible to realize real-time on-site detection and traceability of straw burning by combining LIBS technique and tuned BP model, and it has broad application prospects in the field of atmospheric environment detection.
Funding
The Natural Science Foundation of the Jiangsu Higher Education Institutions of China (22KJD140003); Project funded by China Postdoctoral Science Foundation (2023M741777); Ph.D. Project supported by the Jinling Institute of Technology (jit-b-201814).
Disclosure
The authors declare that there are no conflicts of interest related to this article.
Data Availability
Data underlying the results presented in this paper are not publicly available at this time but may be obtained from the corresponding author upon reasonable request.
References
- He, H. B.; Wang, Z. Y.; Yan, J.; et al. Enhanced Biomethane Generation from the Anaerobic Digestion of Wilted Corn Straw Via Control in Mesophilic and Thermophilic Temperature Intervals. Fuel 2023, 349, 128616. DOI: 10.1016/j.fuel.2023.128616
- Liu, W.; Pang, J.; Wu, D.; et al. Hydrogen Production by a Novel Klebsiella Pneumoniae Strain from Sheep Rumen Uses Corn Straw as Substrate. Energy 2023, 282, 128210. DOI: 10.1016/J.ENERGY.2023.128210.
- Tian, X.; Ren, B.; Xie, P. H.; et al. The Vertical Distribution and Potential Sources of Aerosols in the Yangtze River Delta Region of China During Open Straw Burning. Sci. Total Environ. 2022, 849, 157749. DOI: 10.1016/J.SCITOTENV.2022.157749.
- Méndez, L. C.; Javier Fernández, M. L.; González, G. C.; Pisonero, J.; Bordel, N. Novel Optical Method Based on Nebulization Assisted Laser Induced Plasma on Inexpensive Paper Substrates for Online Determination of Halogens and Metals in Liquid Samples. Opt. Laser Technol. 2023, 164, 109536. DOI: 10.1016/J.OPTLASTEC.2023.109536.
- Wan, E. L.; Zhang, Q. H.; Li, L.; et al. The Online in Situ Detection of Indoor Air Pollution Via Laser Induced Breakdown Spectroscopy and Single Particle Aerosol Mass Spectrometer Technology. Opt. Lasers Eng. 2024, 174, 107974. DOI:10.1016/J.OPTLASENG.2023.107974
- Yin, W. Y.; Liu, Y. Z.; Zhang, Q. H.; et al. Online in Situ Detection of Multiple Elements and Analysis of Heavy Metals in The Incense Smoke and Ash. Opt. Eng. 2020, 59, 026105. DOI: 10.1117/1.OE.59.2.026105.
- Tian, L. P.; Shen, L. B.; Tian, D. P.; et al. Rare Earth Metals Detection and Recognition Based on Laser Induced Breakdown Spectroscopy and Machine Learning. Opt. Express 2023, 31 (12), 20545–20558. DOI: 10.1364/OE.493905
- Nouman, K. M.; Wang, Q.; Idrees, B. S.; et al. Evaluation of Medicinal Plants Using Laser-Induced Breakdown Spectroscopy (LIBS) Combined with Chemometric Techniques. Lasers Med. Sci. 2023, 38 (1), 149. DOI: 10.1007/S10103-023-03805-2.
- Ye, Y. P.; Wan, E. L.; Sun, Z. M.; et al. Online Detection and Source Tracing of Crop Straw Burning. J. Laser Appl. 2022, 34, 042049. DOI: 10.2351/7.0000866
- Chu, Y. W.; Tang, S. S.; Ma, S. X.; et al. Accuracy and Stability Improvement for Meat Species Identification Using Multiplicative Scatter Correction and Laser-Induced Breakdown Spectroscopy. Opt. Express 2018, 26, 10119–10127A. DOI: 10.1364/OE.26.010119.
- He, J.; Pan, C. Y.; Liu, Y.; Du, X. W. Quantitative Analysis of Carbon with Laser-Induced Breakdown Spectroscopy (LIBS) Using Genetic Algorithm and Back Propagation Neural Network Models. Appl. Spectrosc. 2019, 73 (6), 678-686. DOI: 10.1177/0003702819829555.
- National Institute of Standards and Technology, “NIST Chemistry WebBook”, http://webbook.nist.gov/chemistry/form-ser/.
- Li, X. L.; Kong, W. W.; Liu, X. L.; et al. Application of Laser-Induced Breakdown Spectroscopy Coupled with Spectral Matrix and Convolutional Neural Network for Identifying Geographical Origins Of Gentiana Rigescens Franch. Front. Artif. Intell. 2021, 4, 735533. DOI: 10.3389/FRAI.2021.735533.
- Rao, A. P.; Jenkins, P. R.; Auxier, J. D.; Shattan, M. B.; Patnaik, A. K. Development of Advanced Machine Learning Models for Analysis of Plutonium Surrogate Optical Emission Spectra. App. Optics 2022, 61 (7), D30–D38. DOI: 10.1364/AO.444093.
- Ali, S. D.; Dibyendu, M. Deep Learning Models for Data-Driven Laser Induced Breakdown Spectroscopy (LIBS) Analysis of Interstitial Oxygen Impurities in Czochralski-Si Crystals. Appl. Spectrosc. 2022, 76 (6), 37028221085640. DOI: 10.1177/00037028221085640.
- Li, M.; Ruan, F.; Li, R. et al. In Situ Simultaneous Quantitative Analysis Multi-Elements of Archaeological Ceramics Via Laser-Induced Breakdown Spectroscopy Combined with Machine Learning Strategy. Microchemical J. 2022, 182, 107928. DOI: 10.1016/J.MICROC.2022.107928.
- Song, W. R.; Afgan, M. S.; Yun, Y. et al. Spectral Knowledge-Based Regression for Laser-Induced Breakdown Spectroscopy Quantitative Analysis. Expert Syst. Appl. 2022, 205, 117756. DOI: 10.1016/J.ESWA.2022.117756.
- Cho, H.; Kim, Y.; Lee, E. et al. Basic Enhancement Strategies When Using Bayesian Optimization for Hyperparameter Tuning of Deep Neural Networks. IEEE Access 2020, 8, 52588-52608. DOI: 10.1109/access.2020.2981072.
Lingbin Shen, Liping Tian, Dongpeng Tian, Hang Ji, and Yuzhu Liu are with the School of Network and Communication Engineering at Jinling Institute of Technology, in Nanjing, China, and the Key Laboratory of Meteorological Disaster, Ministry of Education (KLME), Joint International Research Laboratory of Climate and Environment Change (ILCEC), Collaborative Innovation Center on Forecast and Evaluation of Meteorological Disasters (CIC-FEMD) of Nanjing University of Information Science and Technology, in Nanjing, China. Lingbin Shen and Liping Tian are also with the School of Network and Communication Engineering at Jinling Institute of Technology, in Nanjing, China, and the Key Laboratory of Meteorological Disaster, Ministry of Education (KLME), Joint International Research Laboratory of Climate and Environment Change (ILCEC), Collaborative Innovation Center on Forecast and Evaluation of Meteorological Disasters of Nanjing University of Information Science and Technology, in Nanjing, China. Direct correspondence to:
Advertisement
Related Content
Advertisement


Advertisement
Advertisement
Trending on Spectroscopy Online
1
X-Ray Spectroscopy Analysis: Techniques and Applications Across Science and Industry
2
Reading the Heat of the Giza Pyramids with Infrared Thermography
3
Educating Students on Spectroscopy
4
Submicron IR Detects and Localizes Microplastics in Biological Samples
5