Phosphorylation Site Localization Using Probability-Based Scoring
Special Issues
The development of a phosphorylation probability scoring tool in an automated data search engine resolves ambiguity in site localization when compared to manual methods.
Protein phosphorylation is a reversible process of great importance to researchers in nearly every field of biology. Protein phosphorylation refers to the process by which enzymes termed kinases covalently modify proteins at specific residues (mostly serine, threonine, and tyrosine), affecting protein function, localization, stability, or interactions. Abnormal activation of kinases is a hallmark of many diseases including cancer, such that kinase inhibitors are currently a useful therapeutic pressure point for intervention (1).
In drug discovery and development research, scientists can determine the effectiveness of a particular drug by determining the phosphorylation status of substrate proteins in immortalized cell lines. Before the widespread availability of mass spectrometry (MS), this information was obtainable primarily through the use of phosphospecific antibodies. Today, with the use of MS in proteomics, researchers are now able to identify and characterize protein phosphorylation on a large scale (2). Translational proteomics technology has evolved specifically to characterize low-abundance proteins and protein posttranslational modifications (PTMs) accurately in complex cell lysates, in contrast to first generation proteomics, which optimized for simpler protein mixtures.
Identifying sites of protein phosphorylation in data sets generated by MS instrumentation traditionally has required manual validation to control for error. As technology improves and the amount of data increases, this practice has become impractical. Searching against a composite target/decoy database containing all protein sequences in both forward and reverse orientations (Figure 1) can simplify the process of estimating the error rate of peptide spectral matches (PSMs). The target/decoy strategy is based upon the principle that incorrect matches have an equal probability of being derived from either the target or the decoy database. By definition, 100% of correctly assigned spectra should be derived from the forward database, whereas incorrectly assigned (random) spectra should have an equal chance of being derived from either the forward or reversed database. Filtering of the entire data set in an unbiased way to enrich for correct matches provides a final list in which the false discovery rate can be estimated along with many other parameters (3).


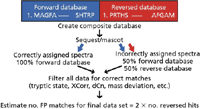
Figure 1: Data from reference 5, in which the probability-based score is compared to commercially available search engines: A composite database composed of normal (target) and reversed (decoy) protein sequences is created for searching MS-MS spectra.
In this article, the use of a probability-based score that measures the likelihood of correct phosphorylation site localization based on the presence and intensity of site-determining ions in MS-MS spectra is explored (4). Data from that same paper is presented to demonstrate the capability of the probability-based score (termed Ascore) to identify phosphorylation site localization as compared to standard search engines. Additionally, the potential benefits of automating the process by using this technology as part of an integrated data search engine (SEQUEST 3G, Sage-N Research, Milpitas, California) designed to accurately identify proteins and protein modifications in biological samples using MS data will be discussed.
Experimental
Protein (4 mg) from nocadozole-arrested HeLa cell lysate was separated by strong-cation-exchange chromatography using a preparative 10% SDS-PAGE gel. The gel was stopped when the buffer front reached 5 cm and lightly stained with Coomassie blue. The entire gel was cut into six regions, diced into small pieces, placed in 15-mL tubes, and digested with trypsin. Extracts were completely dried in a vacuum concentrator and stored at –20 °C.
Extracted peptides were separated by strong-cation-exchange chromatography using a Polysulfoethyl Aspartamide (5-μm beads, 200 Å) column (200 mm × 3 mm, PolyLC, Columbia, Maryland). Early eluted strong-cation-exchange fractions from minutes 2–18 for each gel region were collected, combined into four samples, desalted offline using C18 solid-phase extraction (SPE) columns (Vydac, Deerfield, Illinois), and completely dried.
Liquid chromatography coupled with MS-MS (LC–MS-MS) was performed using the LTQ FT (Thermo Fisher Scientific, San Jose, California) hybrid linear ion trap coupled with a 7-Tesla Fourier-transform ion cyclotron resonance (FT-ICR) mass spectrometer (Thermo Fisher Scientific). The 24 samples were loaded for 15 min using a Famos autosampler (LC Packings, The Netherlands) onto a hand-poured fused-silica capillary column (18 cm × 125 μm) packed with MagicC18aQ resin (5 μm, 200 Å) using an 1100 series binary pump (Agilent Technologies, Santa Clara, California) with an in-line flow splitter. Chromatography was developed using a binary gradient at 400 nL/min of 5–32% solvent B for 35 min (solvent A, 0.25% formic acid; solvent B, 0.1% formic acid, 97% acetonitrile). A total of 10 MS-MS spectra were acquired in a data-dependent fashion from a FT-MS master spectrum (400–1800 m/z at a resolution setting of 105) with an automatic gain control (AGC) target of 3 × 106. Charge-state screening was used to reject singly charged species, and a threshold of 1500 counts was required to trigger an MS-MS spectrum. If a precursor loss of 49 m/z was observed within the two most intense peaks with a threshold of 700 counts within the MS-MS spectrum, an MS3 scan was triggered. When possible, the LTQ and FT-ICR systems were operated in parallel processing mode.
Database searching and data processing. To fully utilize high mass accuracy FT-MS master spectra, Beausoleil and colleagues created in-house software to extract precursor charge-state and monoisotopic mass from isotopic envelope information. To enhance isotopic envelope accuracy, the presence of the precursor ion from five FT-MS spectra upstream and downstream of the master spectrum used for MS-MS were determined. A weighted average of the consecutive spectra containing the precursor ion was then used to extract the charge-state and monoisotopic mass information for database searching.
MS-MS spectra were searched using the Sequest-Sorcerer algorithm (version 27 rev 12, Sage-N-Research) against either a composite database containing the human IPI protein database and its reversed complement, or the human IPI protein database alone with enabled software, which reversed peptides using the algorithm on-the-fly. Unless otherwise stated, search parameters included partially tryptic specificity; a mass tolerance of 50 ppm; a static modification of 57.0214 on cysteine; and dynamic modifications of 79.9663 on serine, threonine, and tyrosine, and 15.9949 on methionine. Mascot searches (Unix 2.1) were performed using the same databases, tolerances, and modifications but were searched fully tryptic because partially tryptic searches were less sensitive. High mass accuracy precursor ions for MS3 spectra were created by subtracting 97.9763 Da from the corresponding MS2 MH+ value. MS3 spectra were searched the same way on a 19-node Linux cluster running the previously mentioned algorithm with an additional dynamic modification of –18.0106 on serine and threonine residues.
To take advantage of data generated by strong-cation-exchange chromatography, peptide solution charge was used as a filter. Solution charge can be defined as the sum of all charges on a peptide at pH 2.7. Specific Xcorr, ppm, and solution charge cutoffs were empirically determined for each gel region (a combination of four LC–MS-MS runs per gel region) to maximize the number of accepted PSMs, while maintaining a combined error rate of 1% for the entire data set. For low molecular weight gel regions (E and F), slightly higher false-positive rates were tolerated without dramatically affecting the overall false-positive rate. Ascores were calculated for each PSM in the data set in batch format using in-house software.
Results and Discussion
The 1761 phosphorylation sites detected came from both localized (Ascore >19; 1079 sites) and ambiguous (Ascore < 19; 682 sites) phosphopeptides. Ambiguous sites still contained viable and identified phosphopeptides, but site localization was at lower certainty levels. In these cases, an ambiguous site was not allowed to count for more than one site regardless of the number of MS-MS spectra or potential site localizations for this peptide.
Precise phosphorylation site localization can be difficult when multiple serine, threonine, and tyrosine residues exist within a single peptide (Figure 2a). For ambiguity between potential phosphorylation sites to be resolved, fragment ions exclusive to a specific site location must be identified to uniquely assign a site to a specific residue. These specific fragment ions were referred to as "site-determining ions." The automated approach identifies phosphorylation site location by determining the most likely phosphorylation site candidates (Figure 2b) and calculating the probability of correct phosphorylation site location based only upon the likelihood of identifying site-determining ions compared to random chance (Figure 2c).


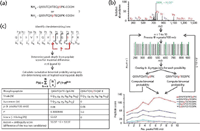
Figure 2: (a) This phosphopeptide is from zinc finger protein 638. (b) General scheme for calculating a probability-based ion matching score (Peptide Score) for each potential phosphorylation site. The tandem mass (MS/MS) spectrum for the phosphopeptide from panel a is shown. (c) The Ascore is a probability-based metric that measures the likelihood that a difference in site-determining ions between two site positions was matched by random chance. In this example, only six b- or y-type ions could potentially differentiate the two phosphorylation sites.
Figure 2a shows a candidate phosphopeptide containing multiple possibilities for phosphorylation site location. The MS-MS spectrum for this peptide was first separated into windows of 100 m/z units. Within each window, only the top i peaks were retained by intensity, where i represented the peak depth. Predicted b- and y-type ions for each possibility were then overlaid with the processed spectrum. The cumulative binomial probability P was calculated using the number of trials N, the number of successes n, and the probability of success p as follows:


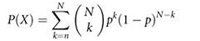
where P represents the probability of randomly matching at least the given number of fragment ions to the MS-MS spectrum. The total number of trials N equaled the total number of fragment ions for the given peptide. The total number of successes n equaled the number of ions matched to the spectrum. Within a given window, the probability of matching a peak p was equal to i/100. For example, where i = 1, p = 0.01 with an ion tolerance of 0.5 m/z. A human readable score was calculated by multiplying –10 by the log(P). This entire process was repeated for i + 1, while i ≤ 10. Scores were then plotted as shown in Figure 2b for each possible phosphorylation site. A weighted average of all ten scores is called the peptide score.
For precise phosphorylation site assignment, the cumulative binomial probability of identifying site-determining b- and y-type ions was calculated for the two highest-scoring site locations (Figure 3c). The process was applied at the earliest peak depth that represented the maximum difference between the two highest-scoring site locations determined by using the Peptide Score as described earlier. In the example shown in Figure 2b, the earliest maximal peak depth was 6. The cumulative binomial probability for matching only the site-determining ions was calculated using the same method outlined earlier with one exception: the total number of trials N was equal to the total number of site-determining ions. The probabilities for the top two candidates were converted into human readable scores and subtracted from each other. The resultant score is a metric that measures the likelihood of matching a difference of at least the number of matched site-determining ions by chance from the top two candidate sites and has been termed the ambiguity score (Ascore). An Ascore of 20 (P = 0.01) should result in the site being localized with 99% certainty.


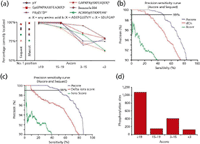
Figure 3: (a) The number of phosphopeptides with the correct site localization varied between 75% and 98% for Sequest-Sorcerer no. 1 hits and 75â99% for Mascot no. 1. Greater than 99.8% of peptides with Ascore 19 were localized correctly irrespective of the data set. pS, phosphoserine;pY, phospho-tyrosine; and pT, phospho-threonine. (b) Precision and sensitivity curve comparison of Sequest dCn (red) XCorr (green) and Ascore (blue) for all combined data sets of known phosphorylation sites. (c) Precision and sensitivity curve comparison of Mascot delta-ions score (red) ion score (green) and Ascore (blue) for all combined data sets of known phosphorylation sites. (d) Distribution of Ascore values for all nonredundant phosphopeptides identified in nocadozole-arrested HeLa cell lysate.
To validate the Ascore, six data sets were analyzed (>3500 MS-MS spectra) from phosphopeptides with known phosphorylation site locations. Each data set was required to contain more than one possible site of phosphorylation, with an average of 3.6 phosphorylatable residues per peptide. These data were generated from three separate phosphopeptide libraries, three antibody immunoprecipitation experiments, and a previously published data set (5). For these data sets, neither Sequest-Sorcerer nor Mascot was able to localize 100% of the sites correctly, and neither algorithm provided evidence to suggest which peptides were not correctly localized, demonstrating the need for additional scoring criteria. The success rates of the algorithm used ranged from 75% to 98% (Figure 3a), and Mascot success rates ranged from 75% to 99% (Figure 3a). The Ascore method was then evaluated and compared the results of the two commercially available search engines. It was found that at every degree of precision for correct phosphorylation site localization, the Ascore provided an increase in sensitivity over the search engines (Figures 3b and 3c).
It was then attempted to reach >99% certainty with the search engines by taking the first place selection and applying additional filtering criteria to the combined data sets of known phosphorylation sites. To achieve >99% certainty with the search engine required the use of a strong delta correlation filter ( 0.15). At the same confidence level, the Ascore method showed a substantial improvement, localizing twofold more phosphopeptides (Figure 3b). Furthermore, the delta correlation filter failed to clearly define those phosphopeptides that were improperly localized or lacked proper localization information. As expected, it was also found that XCorr did not have a substantial effect on phosphorylation site localization. For the other search engine, there was no defined metric that could reach >99% certainty for phosphorylation site placement. As an alternative approach, a normalized delta-ions score was created by taking the difference in the ions score for the top two ranking peptides and dividing that difference by the first ranking peptide's ion score. To reach >99% certainty required a delta-ions score of 0.4. At the same confidence level, the Ascore method showed a substantial improvement, localizing 4.1-fold more phosphopeptides (Figure 3c).
Conclusion
Measuring the probability of correct phosphorylation site localization based upon the presence and intensity of site-determining ions in MS-MS spectra holds great promise for the field of proteomics. Unlike any other sequencing algorithm, calculating an Ascore for each phosphorylation site and evaluating several different threshold values made it possible to accurately characterize every phosphorylation site in any data set in terms of phosphorylation site localization and certainty of site assignment. These results clearly suggest that Ascore provides significant advantages for translational proteomics research, especially when studying phosphorylation and protein PTMs in cancer and stem cell research.
Since the conclusion of the Beausoleil et al. study (5), a commercially available version of the Ascore has been integrated into a next-generation data search engine, which automates the process that was conducted manually as described here. The integration of the probability-based score into the search engine described here offers substantial benefits to proteomics researchers. The proteomics platform defines a single common standard for similarity scores, search statistics and file formats to provide a robust foundation that meets the needs of translational research, including support for high-accuracy mass spectrometers and dissociation technologies such as electron-transfer dissociation (ETD). Instead of performing searches on multiple software copies running in separate servers, the search engine can be implemented using a highly sensitive, first-pass filter that reports the top candidates, which can then be rescored at the second pass using more sophisticated, computing-intensive scoring modules. Automating this process offers researchers greater opportunities to accurately identify proteins and protein modifications in biological samples using MS data, providing scientists with an enabling tool in the fight against hard-to-treat diseases such as cancer.
Steven P. Gygi is with Harvard Medical School, Cambridge, Massachusetts.
References
(1) T. Pawson and J.D. Scott, Trends BioChem. Sci. 30, 286–290 (2005).
(2) J.J. Coon, Anal. Chem. 81, 3208 (2009).
(3) J.E. Elias, W. Haas, B.K. Faherty, and S.P. Gygi, Nature Methods 2, 667–675 (2005).
(4) X. Han, A. Aslanian, and J.R. Yates, Current Opin. Chem. Biol. 12(5), 483–490 (2008).
(5) S.A. Beausoleil, J. Villén, S.A. Gerber, J. Rush, and S.P. Gygi, Nature Biotechnol. 24, 1285–1292 (2006).

















Mass Spectrometry for Forensic Analysis: An Interview with Glen Jackson
November 27th 2024As part of “The Future of Forensic Analysis” content series, Spectroscopy sat down with Glen P. Jackson of West Virginia University to talk about the historical development of mass spectrometry in forensic analysis.

Detecting Cancer Biomarkers in Canines: An Interview with Landulfo Silveira Jr.
November 5th 2024Spectroscopy sat down with Landulfo Silveira Jr. of Universidade Anhembi Morumbi-UAM and Center for Innovation, Technology and Education-CITÉ (São Paulo, Brazil) to talk about his team’s latest research using Raman spectroscopy to detect biomarkers of cancer in canine sera.



