Understanding Data Governance, Part II
Data integrity requires a multilayered approach that runs throughout a regulated organization. Here we discuss the laboratory level.
Data integrity requires a multilayered approach that runs throughout a regulated organization. Here we discuss the laboratory level.
In the first part of this series (1), I spoke about data governance at the corporate level. For the second part, I will focus on the laboratory and discuss the impact of the data governance scheme as it cascades down to the processes and systems at the bench.
Line management will be responsible for ensuring that the corporate policies and procedures as well as the requirements for an open culture are communicated down the line to the operational staff as outlined in Table II in Part I. My main focus here will be on data ownership and data stewards because the Internation Society of Pharmaceutical Engineering (ISPE) paper only has a single passing reference to data owners (2), but data ownership is mentioned in the Medicines and Healthcare Products Regulatory Agency (MHRA) and World Health Organization (WHO) data integrity guidance documents (3,4).
How do we get from data governance to data ownership? The WHO data integrity guidance (4) states in Section 4.10, “To ensure that the organization, assimilation, and analysis of data into a format or structure that facilitates evidence-based and reliable decision making, data governance should address data ownership and accountability for data process(es) and risk management of the data life cycle.”
As we can see, a part of data governance is data ownership and accountability for data processes and associated risk management in any data life cycle. Since we are dealing with spectroscopic analysis, we will focus on computerized systems that control a spectrometer. However, do not forget any manual processes in your laboratories that also need assurance of the integrity of records generated.
How do we know who are data owners, and what are their responsibilities? The guidance documents are not much help here, so let’s return to the definitions of data governance in Table I from Part I for some assistance. The nonpharmaceutical definitions listed in the right-hand column show that data governance focuses on defining the rules, roles, and responsibilities for acquisition and management of data. In my opinion, data owners should be responsible for these functions because they should know the process that is automated by the spectrometer. However, there are already two roles for a computerized system defined in Good Automated Manufacturing Practice (GAMP) 5 (5) and Annex 11 (6): the process owner and the system owner. These two roles were originally defined in GAMP 5 (5) and were simplified in Annex 11 (6) as follows:
Process owner:
- The person ultimately responsible for the business process or processes being managed (5).
- The person responsible for the business process (6).
System owner:
- The person ultimately responsible for the availability, support, and maintenance of a system, and for the security of the data residing on the system (5).
- The person responsible for the availability and maintenance of a computerized system and for the security of the data residing on that system (6).
These are the two roles that are defined in the regulations. The split in responsibilities above gives rise to the concept of process owner in the business and system owner in IT. Note that for stand-alone systems, the two sets of responsibilities are merged and the process owner is also the system owner. Hands up for those lucky individuals in this situation!
Can a Process Owner Be a Data Owner?
How should these regulatory roles fit within a data governance framework? Let’s start with the data owner. The obvious fit is for the process owner to be the data owner as well because data are generated and converted to information in the business. Therefore, we could modify the Annex 11 definition of process owner and encompass data ownership as follows: “The person responsible for the business process including the data generated, transformed, and reported by a manual process or a computerized system.”
So, who should be a process or data owner? GAMP 5 gives some guidance that is self-explanatory (5): “This person is usually the head of the functional unit or department that uses the system, although the role should be based on specific knowledge of the process rather than position in the organization.”
One potential area of confusion concerns the name “data owner,” which implies that an individual owns the date rather than the organization that owns the system and the data generated by it. That situation is not so-the organization owns the data, and the data owner is merely the custodian of the data in the system who acts on behalf of the organization. Perhaps data custodian may be a better title for this individual.
Other Data Governance Roles at the System Level
We will look in some more detail within our regulated analytical laboratory at the other roles involved in data ownership. In addition to the data owner, there are two other roles as follows:
- Data stewards: Responsible for enabling the requirements of the data owner for the system. (These people would typically be the power users or system administrators in the laboratory.)
- Technology stewards: Responsible for enabling the IT requirements of the data owner and a person or persons who, for a networked system, is the system owner or reports to the system owner. This role is essential for the segregation of duties and to avoid conflicts of interest when administering the system. Note that this role will not be found in a paper-based process because it is only used when a computerized system is involved.
The responsibilities of each role are listed in Table I and the interactions between these two roles and the data owner are shown in Figure 1. Subject matter experts, some of whom may be either data or technology stewards, are also mentioned in Table I and quality assurance input is only shown in Figure 1 but the responsibilities are many of those presented in Table II from Part I. To map from data governance roles to those currently used in laboratories, I have put titles in brackets in Table I-for example, a data steward is a laboratory administrator.


Figure 1: Data governance at the process and system level.
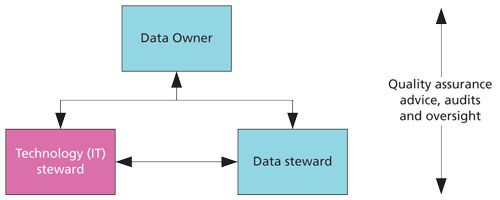
Looking at the three main roles above, you will find two of them are not mentioned in any data integrity guidance document: data steward and technology steward. The role of these stewards, and others, can be seen in the book by Plotkin (7). Why is there a need for data and technology stewards? The answer can be found in the discussion of who should be a process owner in GAMP 5 (5) and outlined above. Typically, the data owner is the head or a section head of a laboratory, but often the work to be done in administering the system will be devolved to others such as super users or lab administrators and IT support staff if the system is connected to the network. This is the normal business process and these individuals are the data and technology stewards. Furthermore, because the data owner will specify the security, data quality, and data integrity requirements for the system, who better to ensure that they have been implemented than the second-person reviewers, another group of data stewards? You’ll remember my comment earlier in this column about the need to integrate data integrity roles with normal business operations. Here is a very good example of that. Take the normal situation and simply reinforce or overlay the data integrity responsibilities on top.
Data Owner
It is important to realize that data integrity and data quality begin at the point of data acquisition by the process and not in the computer center. If data acquisition is compromised by poor working practices or by using an uncalibrated instrument, data integrity is compromised or lost from this point forward. Therefore, the data owner’s responsibilities for a regulated computerized system from the business side include
- Defining what is required of a system in terms of data quality, data integrity, and data security. This process will result either in inputs to the configuration specification for the setting of application policies, writing of standard operating procedures (SOPs) for using the system, or the agreement with IT to support the system (for example, backup, user account management, and so on). This step begins from the start of the analytical procedure.
- Assessment of the system to determine if there are vulnerabilities of the records contained therein. Although a system may be validated, record vulnerabilities may exist that have to be managed (8).
- Development of a remediation plan with the data and technology stewards for any remediation to secure the records and reduce or eliminate data vulnerabilities following the assessment.
- Approve access to the system for new users and changes in access privileges for existing ones for IT administrators to implement.
- Approval or rejection of change control requests.
- Approval for archiving data and removing them from the system.
- Receive feedback from the data stewards of the system of issues involving quality, integrity, and security of the spectroscopic data and implement any modifications of procedures for the data stewards to implement.
That’s the good news for data owners.
Data Steward
The data stewardship concept is defined in the literature as the enabling capability of data governance. Defining different types of stewardship addressing different aspects of the data governance process is also described in the literature (7), but the focus in this column is only on data and technology stewards.
Because the data owner probably will not have the time or the training to implement the requirements for data integrity and quality that they have mandated, implementation is the role of the data stewards for the system:
- The data stewards, in the form of power users or super users, are the first point of contact for user questions for help with the system.
- The stewards will also be instrumental in ensuring the smooth running of the system with processes such as developing custom reports or custom calculations.
- As expert users of the system, they will be responsible for ensuring that the requirements for data integrity and data quality set by the data owner have been implemented and are working.
- They are also responsible for data queries and monitoring data integrity from a system perspective-for example, they are responsible for a regular review of system-level audit trails for system-related issues rather than data integrity problems or aiding quality assurance data integrity audits.
In monitoring the system from the business perspective, data stewards can raise issues for discussion with the data owner to resolve as noted earlier in this section.
Is a Lab Administrator a Data Steward?
Although data stewards are involved with data governance outside of the pharmaceutical industry, we need to see how this role can be overlaid onto the situation in a regulated laboratory. For most systems, either stand-alone or networked, the data owner may not be involved in some of the technical administration of the application such as the generation of spectral libraries, creation of custom reports, and custom calculations or macros. Technical administration is the role of the laboratory administrators. You can see that adding the responsibilities involved for data stewardship in Table I would be a logical step within an overall data governance framework and to integrate governance within the current roles typically used in a laboratory.


Is a Technology Steward a System Owner?
Recall the definition of system owner from Annex 11 as the person who is responsible for the availability and maintenance of a computerized system and for the security of the data residing on that system. This role, in my view, should be performed by the IT department. In particular, the system owner could be the head of the functional IT group responsible for system support. An alternative approach is that the system owner could be in the laboratory or business, but that would only work with larger organizations that have the capacity for the headcount. In smaller organizations, the role of system owner would need to be delegated directly to the IT department under an agreement with the process or data owner.
For a networked application, technology stewards are members of the IT department who would be responsible for the administration of a networked application, logical security, backup or recovery, and other support functions and carry out the responsibilities outlined in Table I. However, if the spectroscopy system is stand-alone and has few users, then the data owner is also the data steward and the technology steward. Three hats and no pay rise.
Segregation of Duties
In this data governance framework, it is important that there is a segregation of duties. For example, there needs to be separation of administrator functions for configuration of the application from the normal analytical users of the system. In addition, access to data files in operating system directories, the system clock and the recycle bin needs to be restricted for laboratory users.
The Short Straw . . .
Look around any regulated laboratory and you will see a data integrity disaster in operation. There are your lovely toys-sorry, spectrometers-that are operated by a software operating on a stand-alone workstation. Do you want the good news or the bad news? Good news? OK, there is none! The bad news comes in a variety of forms:
- You, the data owner, are now also the system owner because the computer is not connected to the network-you are now doing user account management, documenting the configuration of the software, and backing up the data, and this is a conflict of interest.
- It is highly likely that you are using the system as a hybrid by generating electronic records and signing paper printouts.
- Most of your electronic records are stored in directories within the operating system that any user can access by going outside of the operating system and deleting files. Moreover, such users can also access the system clock, which may not be checked; they can also access the recycle bin.
Life is wonderful, if you don’t think about the problems with your software and the electronic records. How do we resolve this situation?
Defining Data Integrity and Security of a System
You may remember from Table I in Part I that the focus was on the access to data and hence the records generated, interpreted, and reported by it. Therefore, you as the data or process owner are responsible for assessing the processes and systems for which you are responsible for the vulnerability of the records over the lifetime of the data. This assessment will be coordinated by the corporate data governance steering committee or their local equivalent.
The aim of this assessment is to identify the vulnerabilities of the records and remediate in two ways:
- Short-term remediation: This process involves quick fixes to ensure that records are protected, such as implementing operating system security to prevent access to the records, the system clock, and the recycle bin. Electronic records with associated metadata should be transferred to the network and be backed up by the IT department. Adding a network card to the workstation should enable the data to be backed up to secure network storage.
- Long-term remediation: This process ensures that the system and the process it automates acquires and manages data to ensure quality, reliability, and integrity of the records. Let’s explore this area briefly now.
The Hybrid System Nightmare
A hybrid system is the worst possible situation because the data owner has to ensure that the electronic records created by the software are linked to the signed paper printouts. Managing and coordinating two disparate media forms over the lifetime of the data is difficult. However, don’t just take my word for it, look at what the WHO data integrity guidance (4) says:
- “Data integrity risks are likely to occur and to be highest when data processes or specific data process steps are . . . hybrid, . . .
- “The use of hybrid systems is discouraged . . .
- “The hybrid approach is likely to be more burdensome than a fully-electronic approach; . . .
- “Replacement of hybrid systems should be a priority.“In the hybrid approach, which is not the preferred approach, paper printouts of original electronic records . . .”
Are you getting the message?
While the aim of short term remediation is to ensure that the record vulnerabilities are reduced to acceptable levels, longer-term replacement of these systems is essential. Again, the aim here is to provide substantial business benefit to the laboratory with the remediation and not just to replace one hybrid system with another as was the case with Part 11 remediation. Automation of a laboratory process must have the aim of improving working practices, speeding up work, and ensuring data integrity. However, if the new laboratory process fails to eliminate the majority of paper records or the way the software works is not managed correctly then all that happens is that the process becomes an automated mess and data integrity cannot be ensured. Back to square one.
The problem is that the majority of spectroscopic systems are very poorly designed. Examples include:
- systems designed to work as a hybrid with no electronic signatures;
- electronic signatures implemented improperly in that the signature is not applied to the record but recorded only as an audit trail entry;
- a system operated as a stand-alone system with no option to work as a networked system that would allow users to review data at a second workstation;
- a system in which data are acquired to a single hard drive and not to a secure network drive;
- a system in which data are managed in directories in the operating system rather than in a database; and
- poor audit trail review functions that highlight if good manufacturing practice (GMP) critical data have been modified or deleted.
Unfortunately, users have not pressured suppliers to ensure that the software is adequate to meet changing regulatory requirements and suppliers only react to market forces.
Data Maturity Model
You will recall in Part 1 of this column, I stated that the primary reason for data governance should be for business rather than regulatory reasons. Again, we step outside of the confines of the regulated world and bring in a wider perspective from the CMMI Institute. Carnegie-Mellon University of Pittsburgh (CMU) has the Software Engineering Institute (SEI) as one of its faculties. The SEI has designed the capability maturity model (CMM) to classify an organization’s software development ability into one of five categories. A further refinement of this model is CMMI for implementation of software within organizations and has given rise to the CMMI Institute. A data maturity model (DMM) has been developed (9). The DMM is a five category model that describes an organization’s maturity for dealing with data and an edited version of this is shown in Table II.


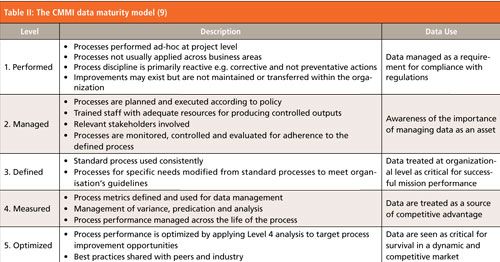
CLICK TABLE TO ENLARGE
As can be seen in Table II, DMM Level 1 is essentially ad hoc management of data, which in a pharmaceutical context is producing and managing data because the regulations say you must. As we go up toward DMM Level 5 there is increasing emphasis on the design of processes that generate and use data effectively as well as a realization that data are a strategic asset and must be managed as such (9). Hence the need for effective data governance from the boardroom down in an organization. At the higher levels, metrics are collected and analyzed not just for monitoring the effectiveness of a data generating process but also to improve it.
One of the aims of data governance should not be a way to keep the regulators happy, but to ensure the survival and growth of organizations.
Don’t Forget Paper Records!
Although the focus in this column has been on electronic records, data governance and data integrity also needs to consider paper records that are created and used in analysis. Chris Burgess and I wrote a recent paper on the control of blank forms (10) to address the regulatory concerns in the WHO, FDA, EMA, and PIC/S guidance documents (4,11–13). Blank forms are not the end of the paper trail-don’t forget balance printouts, laboratory notebooks, equipment logs, and so forth, that need the integrity of their records assured.
Summary
In this two-part column series, we have looked at data governance from the board room to the laboratory bench for a regulated organization. We have discussed the organizational structures, roles, and responsibilities for ensuring data integrity. In the laboratory, data ownership and data stewards are important for ensuring the integrity of data acquired, processed, and reported is complete, consistent, and accurate. However, don’t forget that this column series has focused on computerized systems because we are looking at spectroscopic analysis. There are manual paper-based processes in many laboratories that also have to be analyzed for risk to the records generated and used. As a parting thought, all data governance for data integrity must be integrated into the pharmaceutical quality system for an organization.
Acknowledgments
I would like to thank Mark Newton, Kevin Roberson, Lorrie Schuessler, and Yves Samson for their helpful review comments made in preparation of the two parts of this column.
References
- R.D. McDowall, Spectroscopy32(2), 32–38 (2017).
- J. Avellanet and E. Hitchens, Considerations for a Corporate Data Integrity Program (International Society of Pharmaceutical Engineering, Tampa, Florida, 2016).
- Medicines and Healthcare Products Regulatory Agency, GMP Data Integrity Definitions and Guidance for Industry, 2nd Edition (MHRA, London, England, 2015).
- World Health Organization, WHO Technical Report Series No.996 Annex 5 Guidance on Good Data and Records Management Practices (WHO, Geneva, Switzerland, 2016).
- ISPE, Good Automated Manufacturing Practice (GAMP) Guide Version 5 (International Society for Pharmaceutical Engineering, Tampa, Florida, 2008).
- European Commission Health and Cosumers Directorate-General, EudraLex - Volume 4 Good Manufacturing Practice (GMP) Guidelines, Annex 11 Computerised Systems (European Commission, Brussels, 2011).
- D. Plotkin, Data Stewardship. An Actionable Guide to Effective Data Management and Data Governance (Morgan Kaufman, Waltham, Massachusetts, 2014).
- R.D. McDowall, LCGC Europe30(1), 93–96 (2016).
- Data Management Maturity (DMM) Model (CMMI Institute, Pittsburgh, Pennsylvania, 2014).
- C. Burgess and R.D. McDowall, LCGC Europe29(9), 498–504 (2016).
- Pharmaceutical Inspection Co-operation Scheme, PIC/S PI-041 Draft Good Practices for Data Management and Integrity in Regulated GMP/GDP Environments (PIC/S, Geneva, Switzerland, 2016).
- European Medicines Agency, EMA Questions and Answers: Good Manufacturing Practice: Data Integrity (EMA, 2016, available from: http://www.ema.europa.eu/ema/index.jsp?curl=pages/regulation/general/gmp_q_a.jsp&mid=WC0b01ac058006e06c#section9).
- US Food and Drug Administration, Draft Guidance for Industry Data Integrity and Compliance with cGMP (FDA, Silver Spring, Maryland, 2016).



R.D. McDowall is the Principal of McDowall Consulting and the director of R.D. McDowall Limited, as well as the editor of the “Questions of Quality” column for LCGC Europe, Spectroscopy’s sister magazine. Direct correspondence to: SpectroscopyEdit@UBM.com















