The Long, Complicated, Tedious, and Difficult Route to Principal Components: Part I
In this month's installment, columnists Howard Mark and Jerome Workman, Jr. present the derivation of the principal component algorithm using elementary algebra.



Principal component analysis (PCA) is arguably one of the more, if not actually the most, common methods of multivariate analysis applied to molecular spectroscopy nowadays. Therefore, we decided to present the long, complicated, tedious, and difficult approach for reasons that are good and sufficient, and that we will explain here and now.



Jerome Workman, Jr.
In addition to our own previous column, there are, of course, multiple discussions and presentations of the topic. There are books devoted entirely to the subject (2) and innumerable books whose main topic is statistics, chemometrics, or one or another field of spectroscopy or a related field that include one or more chapters on the topic. A good example is reference 3. All of those publications inevitably present the discussion using the formalism of matrix notation, and for good reason: writing out all the necessary equations otherwise is rather unwieldy. However, unless someone is really, really facile at slinging the matrix equations, matrix algebra loses the intuitive feel that the reader might like to develop for the subject. Those who are really, really facile at slinging matrix equations know who they are and don't need what we're about to do here; this is for the rest of us.



Howard Mark
We ran into a similar situation recently in some previous columns when we found that the presentation of multiple regression using the matrix formulation also was not a very intuitively understandable method of presenting the derivation of the equations needed to formalize the mathematical least squares definition of the multiple linear regression (MLR) algorithm. We found that going "back to the basics" of applying fundamental concepts from algebra, aided by some relatively elementary operations from calculus, was necessary to achieve intuitive clarity (4,5).
So it is with principal components. The presentation of the subject in terms of matrix operations is rigorous and concise, but it also tends to form a barrier that separates the reader from an intuitive understanding of what is going on "under the hood" of the algorithm. After writing these columns for close to 30 years now (starting with "Statistics in Spectroscopy" before moving on to "Chemometrics in Spectroscopy"), one of the points we have come to appreciate is that while we are limited in what we can include in any single column, we can treat any topic at whatever length is necessary by spreading it out over several columns, which is what we plan to do with the explanation of principal component analysis. As described earlier, so many treatments simplify the algorithm past the point of comprehension that it's long past time for the long, complicated, but comprehensible treatment that can be achieved by doing it all (well, mostly, anyway) with a lot of algebra and a little calculus, just as we did with multiple regression.
Therefore, over the next several columns, we will present the derivation of the principal component algorithm using elementary algebra. Now, strictly speaking, our presentation will not be completely algebraic. As we found necessary to do with derivation of MLR, we also will need to introduce some concepts from elementary calculus, in particular the use of derivatives, and the concept that the maximum or minimum of a function occurs at the point where the derivative is zero (but you remember all that, don't you?). For the most part, however, we eschew the use of matrix operations for the main derivations.
We will include some matrix notation for some purposes and goals, however:
- At main junctures, we will include the matrix equation corresponding to the derived result. This will allow readers to compare the result with other, more standard presentations, because the matrix equation will act as a "landmark" in the derivation. This also will allow readers to see algebraically how a result in the standard presentations came about.
- We will use matrix notation for setting up some of the data arrays upon which we will operate. This will provide us with the advantages of clarity and conciseness of expression that matrices provide. For those who are not familiar with basic matrix notation, we have included the basics in Appendix A of this column.
- Much of the analysis can be performed by treating the equations involved one at a time, as though they were univariate. Toward the end of the process, however, we will reach a point at which the analysis can continue and reach the desired goal only by recognizing and dealing with the inherent multivariate nature of the situation. At this point, it will become necessary to use inherently multivariate methodology, which is defined in terms of matrix behavior; thus, we will be forced to deal with matrices as such. That won't happen for a long time, though.
So we will stick primarily to the algebra for the derivations, including portions that seem complex. The apparent complexity, however, is not due to any use of advanced concepts; it is due more to the fact that we have all forgotten most (or, at least, much) of the elementary algebra we once knew rather than because the concepts are so advanced, difficult, or inherently complex. So the actual operations and derivations will be done algebraically to enhance the intuitive clarity that we are striving for.
In the later stages of the derivations, it will become necessary to introduce some results based upon theorems that are inherently multivariate as described earlier, and then we will, of necessity, have to use matrix representations. We've done this sort of thing before, too. For example, in the previously discussed column about MLR (5), we had to introduce the concept of a matrix inversion. Sometimes there is no help for this. If and when it becomes necessary, we will try to minimize the pain and maximize the intuitive comprehension with our descriptions. We'll do our best, but there's only so much we can do.
Some Preliminary Discussion
Principal components have been defined in many ways. One definition that captures the essential characteristics of principal component analysis was presented in reference 6. To paraphrase it slightly:
Principal component analysis is a mathematical technique that generates eigenvectors, corresponding to the eigenvalues of a variance–covariance matrix, that are orthogonal, and unique linear combinations of which account for the largest possible amount of variance of the data with the fewest such linear combinations.
The underlying basis of principal components is that they are a way of reconstructing the data matrix (for example, the spectra) from which they were derived. In this respect they are similar to Taylor series or Fourier series. In all three methods of reconstructing the data, the reconstruction is approximate; using the first term from a Fourier series or the first term from a Taylor series gives some degree of approximation. Using two terms gives a better approximation, and so forth, until sufficiently many terms are included (usually this means as many terms as there are data points in the function, or spectra in a data set), at which point the reconstruction becomes exact. Principal components have this property also. The first principal component gives some degree of approximation, and the approximation gets better and better as more principal components are included in the approximation. Eventually, the reconstruction becomes exact here, also.
There is also a fundamental difference between Taylor (and Fourier) series as compared with principal components, however. The functions used when calculating a Taylor series (polynomials) or Fourier series (trigonometric functions: sines and cosines) involve approximations to the data that are defined by a priori mathematics. When performing this task using principal components, the functions used are defined by, or at least derived from, the data. In this sense, principal component analysis is more nearly akin to spectral subtraction or to Gauss–Jordan curve fitting; both of these are ways of fitting empirical functions (the spectra of the components of a mixture) to the spectra making up the data matrix (normally, the spectra of mixtures).
Principal component analysis is a way to generate empirical functions that similarly can be used to reconstruct a data matrix, except that the functions so derived are abstract (in the sense that they don't necessarily represent any particular feature of the spectra of the components of the mixture comprising the samples whose spectra were measured) and have certain predefined mathematical properties. There are three key properties of the functions resulting from the calculation of principal components:
- Within a set, they are all mutually orthogonal.
- They capture the correlation structure of the data from which they were derived (that is, each principal component "explains" those parts of the data that are correlated with each other).
- They are maximum-variance functions (the first principal component includes more of the variance of the data that any other single function can; the first two principal components include more of the variance of the data than any other two functions can, and so forth).
These properties are not entirely independent. As we'll see when examining the mathematics of the situation, the first two properties are, to some extent, consequences of the third, although they also can exist independently (in other types of data analysis). For example, the sines and cosines comprising a set of Fourier functions are also all mutually orthogonal, although they do not share the property of being maximum-variance functions.
It is the third property that is unique to principal components and that distinguishes it from all other methods of approximating the data. Other functions, such as sines and cosines (Fourier components, generating this term by analogy), are orthogonal, and can be used to "explain," or reconstruct, the data. Other sets of functions, such as Taylor components (again using an analogy to represent the polynomials), also can be used for the same purpose, even though the underlying functions (polynomials in this case) are not necessarily even orthogonal. But principal components will reconstruct the data set from which they were derived better than any other set of functions can, and that is the key defining property of this method of data analysis (although we note that we have not yet defined what "better" means, in this sense).
One further note about principal components being a "maximum variance estimator": As we will see once we get well into it, trying to derive the properties of principal components tends to lead to trivial solutions. Sometimes the trivial solution reached is one in which all the values making up the principal components are zero. This is obviously a minimum variance solution, because the variance of anything multiplied by zero is itself zero, and a variance cannot be less than that.
Another type of trivial solution is one in which the various coefficients making up the principal component become larger and larger without bound (they approach being "infinitely" large). This is certainly one type of maximum variance solution, because the variance also would become "infinitely" large. Certainly infinity is the largest possible amount of variance that anything can have, just as zero is the smallest possible value for variance. This is not a useful solution, nor is it the solution we are seeking. In order to understand the intended meaning of "maximum variance estimators," we need to develop some preliminary results.
Some Preliminary Results
We begin with a review, and some further development, of some of the concepts we discussed earlier, including the analysis of variance of data. Let us start with a data array, as shown in equation 1 (we remind our readers about Appendix A, for those who need it).


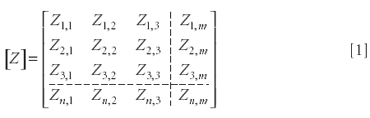
Note: While our basic approach will avoid the use of matrices in the explanations, we will include the matrix expression corresponding to several of the results we derive. There are several reasons for this. One is that upon reading the literature, you will see the matrix formulations, and our including them here will allow you to relate the standard presentations to the underlying mathematical derivations. Another is that toward the end of our presentations, some of the global aspects will become easier to comprehend by avoiding some of the more confusing details (it will be easier to "see the forest without the trees," although as we just said, because you will have both presentations, you can relate them to each other).
Thus, we see that the elements of the data matrix [Z] are designated by Zi,j, and this matrix has n rows and m columns. Generally, in our usage, the columns represent different variables (for example, the absorbance at different wavelengths) and the rows represent different samples. For the sake of keeping our intuition satisfied, we will consider that the rows of matrix [Z] represent spectra of different samples, and the columns represent the absorbance values at the various wavelengths in each of the spectra.
We showed previously (7) that the following relationship holds, for any given variable:


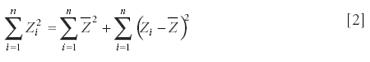
The term


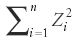
generally is referred to as the total sum of squares (TSS), for obvious reasons. The terms on the right-hand side of equation 2 are called the sum of squares due to the mean (SSM), and the sum of squares due to the differences from the mean, or the sum squared error (SSE). We also had shown, a long time ago, that the mean itself is a least-square estimator of the data from which it was calculated (8). If we take the point of view that the mean is an approximation to the data, or a "prediction" of the data, then the difference Zi – Z-mean is the "error" of the mean as an approximation, and the sum of squares corresponding to that is then the SSE.
Dividing both sides of equation 2 by n – 1 gives us the following equation:


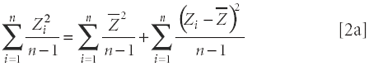
The first two terms of equation 2a are not of particular interest at this time, but the third term, the second one on the right-hand side of equation 2a, can be seen to be the variance of Z, the quantity whose square root is the standard deviation of Z. On the other hand, except for the division (or multiplication by the constant (n – 1)), there is no difference in the basic structure or behavior between equations 2 and 2a.
So for a given dataset, equation 2 shows that the TSS (the left-hand side of equation 2) can be split up into two other sums of squares, shown on the right-hand side of equation 2: the SSM and the SSE that add up to the original, TSS. This operation is known in statistical parlance as the partitioning of sums of squares. Similarly, equation 2a shows that a quantity akin to the variance of the Z also can be split up, into terms that also have a correspondence to quantities that correspond to variances, of the pieces into which the total is split. Therefore, this operation also is called analysis of variance. We will see below how actual variances can be used to perform the same operation.
If the deviations from the mean can be further separated into two meaningful subsets of data, in which the data points from each subset can be put into a one-to-one correspondence, then we can do a further partitioning of the sums of squares. We showed this previously also; if we designate the subsets of the initial partitioning representing Σ (Xi – X-mean)2 as X and Y, then we show that the following relationship holds between two variables (5):


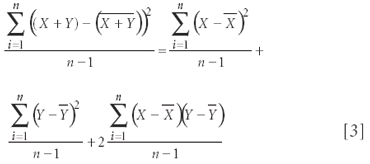
It simplifies the conceptual picture of the situation (and also the notation) if we consider the data after the mean already has been subtracted from the data in the dataset, wavelength by wavelength, and along with it, the SSM. Because for any given data set the mean is constant and therefore the variance of the mean is zero, the subtraction of the mean from the rest of the data makes no change to the further analysis of the variance components of the data set and simplifies the equations by eliminating a useless term. We will therefore perform this simplification, doing it in two steps.
Then we note that the left-hand side of equation 3 is the variance of (X + Y), and the first two terms on the right-hand side of equation 3 are the variances of the X values and Y values separately. The third term is closely related to the correlation coefficient between X and Y. Therefore, if the two variables are uncorrelated (the correlation coefficient = 0), then equation 3 simplifies to


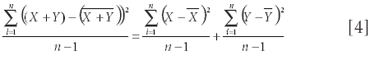
That is, the variance of the sum equals the sum of the variances — we've seen this before, too (8). As before, subtracting the means of the data before doing the partitioning gives us the simplified expression:


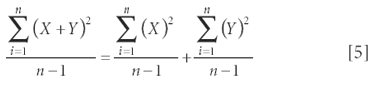
Similarly, as we did with equation 2, we can (in this case) multiply both sides of the equation by n – 1, to achieve


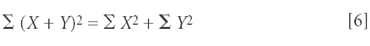
to demonstrate the corresponding relationship between the sums of squares. As in equation 2, there is no fundamental difference between using the sums of squares or using the variances.
Applying this method to the relationship between the spectral data and the predicted values from the approximation made by principal components, we can identify these two pieces of data with the X and Y of equation 6, and so begin our discussion. We will concentrate our attention on the data at one of the wavelengths. Let's consider some arbitrary wavelength, which we'll call wavelength 1, for the sake of simplicity. Let X p,1 (the p subscript standing for "prediction," here) represent the value of a particular principal component at the first wavelength (let's consider only the first principal component). For any value of Xi,j in a matrix [X], in particular a value from the first wavelength (that is, Xj,1), then Xp,1 represents the approximation to the data at the first wavelength represented by the principal component.
As mentioned earlier, we will consider the mean of the data set to have been subtracted from the data. This also has another consequence: in addition to making the mean of the resulting data set zero, it also makes the mean of the data set formed by the approximating functions zero. While it is not critical for the means to be zero, it is critical that they be the same, and making them zero is the easiest way to demonstrate that in fact they are the same, in addition to simplifying the notation.
Making this change of notation, we can write the following identity:


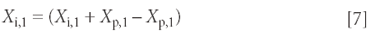
Equation 7 follows immediately from the observation that Xp,1 – Xp,1 equals zero.


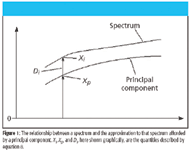
Figure 1
Letting Di,1 = Xi,1 – Xp,1, that is, D represents the difference (also called the error) between the actual data and the approximation, as shown in Figure 1, equation 7 becomes



Adding the contributions from all samples, we obtain:


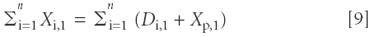
Then, squaring the terms on both sides of equation 9, we get


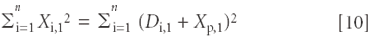
The same development that took us from equation 3 to equation 6 gives the following result, when applied to equation 10:


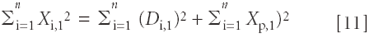
(Exercise for the reader: follow the template of equations 3–6 to show that equation 11 follows from equation 10.)
Let's examine what we have achieved. The term on the left-hand side of equation 11 is the TSS, the total sum of squares due to the variations of the data at the first wavelength in the spectrum. The important part about this expression is that, because it depends solely upon the data set from which it was calculated, it is a constant. It does NOT depend in any way upon whatever mathematical manipulations might be going on elsewhere.
The second term on the right-hand side of equation 11 represents the sum of squares due to the variation of the principal component around the mean value of X (which we have set to zero, but the variance would be the same as if we had not done so), that is, the amount of variance accounted for by the principal component. The first term on the right-hand side, then, represents variance not accounted for by the principal component (that is, the error of the approximation of the data represented by the principal component to this data).
Let's discuss this situation to demonstrate features that will provide us with an intuitive appreciation and confirmation that it is so. First we consider the characteristic of orthogonality. If the cross-product in equation 3 was not zero, then the summations in equations 4 and 5 would not hold. The cross-product term in equation 3 is the key part of the calculation of correlation coefficient between the approximating function Xp,1 and its corresponding error term (the difference between the approximation and the actual data). This in turn would mean that some of the variance in the error term would be correlated to the variance remaining in the data. This cannot be allowed to happen, however, if all the subsequent principal components are to be orthogonal to each other as well as to the one under consideration.
Second, we examine the effect of a principal component being the maximum-variance function. If the errors are not orthogonal to the approximating function, then some of the variance due to the approximating function is included in the variance of the error. As we had seen previously when considering the variance due to the mean (7), the total variance is the sum of the two variances, and removal of one gives a smaller variance. If this were the case, then we could subtract the contribution of the variance of the approximating function from the error, resulting in another function containing more variance, and therefore smaller error. But this contradicts the fact that the principal components have the "maximum variance" property; therefore, the cross-product term must be zero.
We have now put forth two arguments, in addition to the mathematics, giving the conclusion that Σ(Xp,1 – Xi,1) = 0, which is equivalent to demonstrating that the remaining differences between the PCA approximation to the spectra by the first loading are uncorrelated with the loading itself.
Clearly, the same arguments can be made for the data at any wavelength in the matrix [X]; therefore, summing the contributions from the sums of squares at each wavelength gives the total sum of squares for the entire data set.
As mentioned earlier, for a given set of data, the left-hand side of equation 11 is constant, being determined only by the data. The values of the sums of squares on the right-hand side of equation 11, on the other hand, are determined by the values of Xp; given any arbitrary value of Xp, as it becomes a better approximation to the data, sums of squares can be transferred back and forth between the difference (error) term and the term representing the variance included in the principal component, and vice versa.
Clearly, then, because the total sum of squares is constant, the more of the total variance of the data that is accounted for by the function giving rise to the points Xp, the less is left for the error term, because the two terms must add up to the (constant) total variance (or sums of squares).
One more point needs to be made: because all the terms in equation 11 are sums of squares, none of them can be negative. Therefore, neither term on the right-hand side of equation 11 can be greater than the (constant) value on the left-hand side; the absolute maximum value of either term on the right-hand side is the value of the left-hand side. Either or both terms can be less, if both terms have nonzero values.
If the sum of squares due to Xp (SSX) is large, however, then the SSE must be small. Consequently, if SSX is the largest value it can be, then SSE must achieve the smallest value it can have. This is another way of saying that the principal component is the least-square-error estimator of the data, because it is the function that gives rise to a set of errors which, over the whole data set, have the smallest sum-squared error compared to any other function that could be fitted to the data set.
This is the meaning of the earlier statement, which stated that principal components provide the "best" approximation to the data spectra from which they were derived: "best" in the least-squares sense of having the smallest possible sum of squares due to the error. This is the sense in which principal components are "maximum variance estimators": due to equation 11, they are also the least squares estimators of the original data set from which they were calculated. They are not "maximum variance estimators" in some absolute sense, as some discussions of "maximum variance estimators" would seem to imply. As we saw earlier, the true value for the "maximum variance" is infinity. No real data or function can actually achieve that value. So not only is that interpretation arrant nonsense, but it points to the fact that principal components have the maximum variance property only in the sense that they represent the maximum amount of variance that they can take from the data set, by minimizing the sum-squared error term.
The goal of PCA is to find the function(s) that, when multiplied by a suitable set of weighting values and then subtracted row-by-row from the data matrix X, is the best-fitting function. The "best-fitting" function in this sense means that the sum-squared differences (where the differences represent the error of the approximation) between the data matrix and the fitting function is the smallest possible value, compared to any other function that could be used. We will try to retain this terminology, calling principal components "least square" functions. We will explore how the achievement of this property is accomplished, over the next few columns, deliberately making some false starts in order to bring out various underlying characteristics of the data and the principal components: the functions that we intend to use to approximate the data set.
APPENDIX A
Because we will be using matrix notations as we go along, for the sake of completeness, and to help out our readers in translating matrix notation to algebraic notation, we also include some basics of matrix notation and operations. Note that while we illustrate various properties using a matrix of a given size, all the properties presented here generalize to a matrix of any size. More complete discussions of the various topics touched on here, including examples, can be found in previous columns (9–14).
A.1. Matrices arise as representations of ordinary equations. For example, the following pair of equations

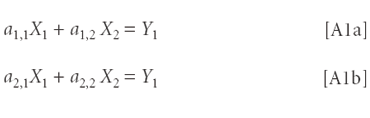
is written in matrix notation by eliminating the operator symbols and writing what's left as matrices:


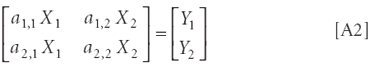
The square brackets indicate that the enclosed expressions constitute a matrix. Matrices are distinguished by being subject to matrix operations. These form a compact notation for extensive sets of equations, and are defined in a way that gives results equivalent to corresponding algebraic operations.
A vector is a matrix in which either the number of rows or the number of columns is unity.
Special Matrices
Some special matrices are defined independently. Examples are
A.3. The zero matrix:



All elements are zero. When multiplied by any other matrix (see below for matrix multiplication), the result is a zero matrix.
A.4. The unit matrix:



All elements are zero except those along the main diagonal, which are 1 (one). When multiplied by any other matrix (see below for matrix multiplication), the result is the same as the other matrix.
A.5. The diagonal matrix:


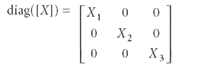
Premultiplying another matrix by a diagonal matrix causes each row of the other matrix to be multiplied by the corresponding row of the diagonal matrix. Postmultiplying another matrix by a diagonal matrix causes the columns of the other matrix to be multiplied by the corresponding column of the diagonal matrix.
Key Matrix Operations
A.6. Matrix transpose (normally indicated as [A]' or [A]T ): rows and columns of the matrix change places. For example, a row vector (a matrix with only one row and n columns) becomes a column vector (a matrix with the same entries, but arranged as a single column containing the same n rows):



A.7. Matrix addition:


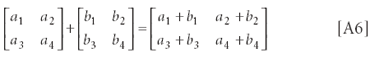
The result is the term-by-term sum of the matrices being added.
A.8. Matrix subtraction is similar, the result being the difference between the corresponding elements of the matrices being subtracted.
A.9. Multiplication by a constant: every element in the matrix is multiplied by the same constant.


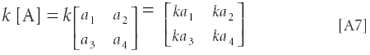
A.10. Matrix multiplication: This has no direct correspondence in algebra. As an example, consider the two matrices [a] and [b]:


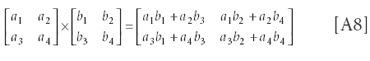
The term in the ith row and jth column of the result matrix is the sum of the products of the terms in the ith row of the first matrix with the terms in the jth column of the second matrix. Because of this, matrix multiplication does not in general commute. For example, if [A] = [a1 a2]; then:
Computing the matrix product one way gives:


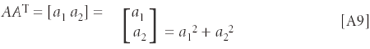
which would typically be a simple constant.
On the other hand, computing it the other way:

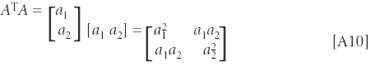
Note that the dimensions of the result matrices are different in the two cases, to say nothing of the values of the result terms.
As another example: the matrix equation A2 earlier:


can be written as follows:



(Exercise for the reader: check this out by multiplying out the left-hand side of equation A11 and showing that equation A2 is recovered.)
A.11. Matrix division: matrix division as such is not defined. An equivalent role is played by the inverse matrix (or matrix inverse). A matrix inverse is indicated by a –1 exponent on a matrix. For example, the inverse of a matrix [X] is written as [X]–1 . The inverse of a matrix is a matrix that has following property:



The inverse of a matrix can only be calculated for a matrix that is square (that is, it has an equal number of rows and columns). Because we will not be using matrix inverses in our discussion of principal components, we include it only for the sake of completeness, and will not discuss here how they can be obtained, although we have touched on that topic previously (10).
Jerome Workman, Jr. serves on the Editorial Advisory Board of Spectroscopy and is director of research and technology for the Molecular Spectroscopy & Microanalysis division of Thermo Fisher Scientific. He can be reached by e-mail at: jerry.workman@thermo.com.
Howard Mark serves on the Editorial Advisory Board of Spectroscopy and runs a consulting service, Mark Electronics (Suffern, NY). He can be reached via e-mail: hlmark@prodigy.net.
References
(1) J. Workman and H. Mark, Spectroscopy 12(6), 22–23 (1997).
(2) E.R. Malinowski, Factor Analysis in Chemistry, 2nd ed. (John Wiley & Sons, New York, 1991).
(3) D. Burns and E. Ciurczak, Handbook of Near-Infrared Analysis, 2nd ed., in Practical Spectroscopy Series (Marcel Dekker, New York, 2001), p. 814.
(4) H. Mark and J. Workman, Spectroscopy 21(5), 34–38 (2006).
(5) H. Mark and J. Workman, Spectroscopy 21(6), 34–36 (2006).
(6) H. Mark, "Data Analysis: Multilinear Regression and Principal Components Analysis," in Handbook of Near-Infrared Analysis, D. Burns and E. Ciurczak, Eds. (Marcel Dekker, New York, 1992), pp. 107–158.
(7) J. Workman and H. Mark, Spectroscopy 3(3), 40–42 (1988).
(8) H. Mark and J. Workman, Spectroscopy 2(5), 52–57 (1987).
(9) J. Workman and H. Mark, Spectroscopy 8(9), 16–20 (1993).
(10) H. Mark and J. Workman, Spectroscopy 8(7), 16–19 (1993).
(11) J. Workman and H. Mark, Spectroscopy 8(8), 16–18 (1993).
(12) J. Workman and H. Mark, Spectroscopy 9(1), 16–29 (1994).
(13) J. Workman and H. Mark, Spectroscopy 9(4), 18–19 (1994).
(14) J. Workman and H. Mark, Spectroscopy 9(5), 22–23 (1994).
















