The Use of Novel Software for the Identification of Trace Compounds in Complex Mixtures
Special Issues
Many volatile organic compounds (VOCs) found in a variety of consumer products are potentially harmful to human health and the environment. Within industry, to regulate product safety and quality, methods for measuring specific VOCs in a product, typically by thermal desorption gas chromatography–mass spectrometry (TD-GC–MS), are implemented. Such analysis provides a comprehensive VOC profile. However, the nature of some products, such as food, can be chemically complex. Within this complexity, trace-level or coeluting compounds can be difficult or time-consuming to identify. As a potential solution, new software tools are being developed to automate interpretation of the data.
In response to increasing concern regarding the detrimental effect of some volatile organic compounds (VOCs), there is growing demand within industry to detect and identify specific VOCs in consumer products. The food industry is a good example of this, with the advent of various regulations involving flavor composition, taint, and contamination.
Typical VOC analyses of food samples are performed by thermal desorption-gas chromatography–mass spectrometry (TD-GC–MS) (1). TD is a VOC extraction-concentration technique used to observe the widest possible range of VOCs, including those at trace-level, in one run. A food sample is inherently chemically complex, comprising an array of high abundance to trace-level compounds. Within a convoluted VOC profile, the identification of specific compounds, particularly those at trace level, by traditional library searching can be difficult, inaccurate, and time consuming.
This problem is not limited to the food industry. Construction materials (2), cleaning products, and perfumed goods are all chemically complex products that are subject to various regulations. To speed up analysis times and ensure products conform to regulations, new software tools are being developed (3). Such software processes the GC–MS data to identify target VOCs automatically from a specified list of compounds (for example, those specified by a certain regulation), and generate a report of target compounds found. To interrogate the data efficiently and address problems such as matrix effects and coelution so that accurate results are produced, this software needs to adopt a powerful chemometric approach.
To assess the ability of this new software to detect specific VOCs in a complex food sample, potato chips were analyzed for the presence of some specific pyrazines. Pyrazines are VOCs that are responsible for flavoring in a variety of foods; these compounds are not regulated, however, due to their "meaty" and "potato-like" flavors, they are likely to be present in potato chips, thereby providing a suitable indicator of the efficiency of the software.
Method
For VOC extraction, a crushed sample (~5 g) of potato chips was placed into a chamber of a thermal chamber accessory (Micro-Chamber/Thermal Extractor, Markes International Ltd., Cardiff, UK). The chamber was heated to 40 °C and a purge gas of helium was applied at a flow rate of 40 mL/min for 25 min to allow equilibration. Air exhausting from the chamber was then collected for 10 min onto a 3.5 in. × 6.4 mm o.d. TD tube (Markes International) containing Tenax TA (Buchem BV, The Netherlands) as the retaining sorbent. Trapped emissions were thermally desorbed on UNITY 2 (Markes International) and analyzed by GC–TOF-MS (BenchTOF-dx (ALMSCO International Ltd., UK) under the following conditions:
TD
Desorption temp: 300 °C for 5 min
Trap: General purpose trap (Markes International)
Trap low temp: 0 °C
Trap high temp: 320 °C
Split: Single split 20:1
GC
Oven: 40 °C (2 min), 20 °C/min to 240 °C (2 min)
Run time: 14 min
Column: HP-INNOWax Polyethylene Glycol 30 m × 250 µm × 0.25 µm
Initial flow: 1.5 mL/min
MS
Transfer line temp: 250 °C
Ion source temp: 200 °C
Before data analysis, a library of three target compounds (dimethyl pyrazine, diethyl pyrazine, and ethyl methyl pyrazine) was created in the target identification software (TargetView, ALMSCO International).
Postrun, the GC–MS datafile was imported into the software. A range of MS file formats can be imported, however, in order to retain the original data, a new version for internal processing is created. The software then interrogated the total ion chromatogram (TIC) for target compounds. The automated stages of processing are as follows.
Dynamic background compensation: The software first applies a dynamic background compensation (DBC) algorithm to the data. The eradication of background effects is fundamental to ensure the precision of data-mining. Any background "noise" — ions that are not contributing towards TIC peaks, including interference from column bleed, air and water offset, and so forth — must be suppressed in order for the software to process real peak data for accurate compound identification. The DBC plot is displayed in the software's user interface.
Spectral deconvolution: Subsequent to DBC, spectral deconvolution is applied to the TIC. This provides distinct compound spectra for the final step of compound identification. Where coelution occurs, spectral deconvolution processes the data for every scan and scan-set across the peak and assigns ions to the appropriate component. Conventional deconvolution methods are adversely affected by matrix effects from the sample; however the initial DBC stage of the software alleviates this.


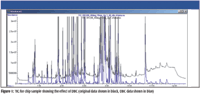
Figure 1
PCA: PCA is the final stage of the automated process. Advanced chemometrics are applied to the deconvolved spectra to highlight characteristic ion fragmentation patterns, which are then compared to the compound spectra of the target library to determine matches. A match coefficient is calculated for each target analyte ranging from 0–1. The higher the coefficient, the more reliable the result; however, compounds with a match coefficient below a user selectable value (e.g., 0.8) can be excluded from the final report to enhance confidence in the results.


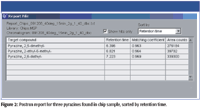
Figure 2
After processing, the software produces a report of target compounds found in the TIC.
Results and Discussion
As the original GC–MS datafile is retained, the pre- and post-background compensated TICs could be observed for comparison (Figure 1). The result is a significantly improved baseline with enhanced compound spectral purity.
As expected due to the nature of the sample, Figure 1 indicates a high sample load from the TD system into the GC–MS. This is reflected in the abundance scale, which ultimately extends to 1+e8. The large concentration of some components in the sample can make the identification of coeluted, trace-level compounds much more challenging. Before deconvolution, attempting to identify compounds by library-searching spectra obtained from overlapping peaks would be likely to result in incorrect and unreliable matches.


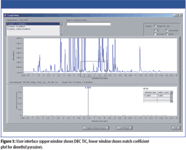
Figure 3
Target compounds found were observed by generating a postrun report (Figure 2). The three pyrazines were identified in the sample, each with very high match coefficients (>0.96). Here, the information was sorted by retention time.
Figure 3 shows the user interface of the software, comprising an upper window showing the DBC TIC and a lower window displaying a match coefficient plot for a specified target compound (in this instance dimethyl pyrazine) with respect to retention time. To determine how this high match value was calculated, the deconvolved (apex) spectrum for dimethyl pyrazine was directly compared to the library entry spectrum within the software (Figure 4). Strong similarity between the spectra was seen, which resulted in the high match value (0.963).


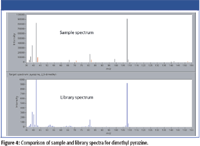
Figure 4
To cross-check the validity of the result produced by the software, the sample spectrum was searched against a commercial database (NIST). Figure 5 represents the NIST search result, which indicated a high probability, first hit for dimethyl pyrazine.
So that individual compounds in the TIC could be viewed, the upper display was configured to show an overlaid histogram plot (HPlot) in which compounds are represented by red bars. The HPlot can be configured to show "target hits only" or "all components." From this overlay, the degree of coelution can be observed. Additionally, the bar height provides a representation of peak area. The area highlighted in Figure 3 is enlarged in Figure 6 to display the HPlot overlay for target compounds found. The three red bars represent the three target pyrazines identified in the chip sample. The red bars, relative to TIC peaks, indicate that the compounds are present at a very low concentration and are coelutedwith unknown compounds.


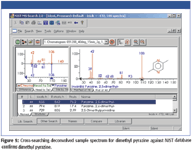
Figure 5
The HPlot was then configured to show all compounds in the sample (as opposed to just targets). From this, the degree of coelution could be observed. Figure 7 shows the location of the lowest concentration target compound (ethyl methyl pyrazine, labeled "T"'), which is coeluted with three other unknown components. Despite the high coelution and low concentration, the match coefficient provided for this compound is very high (0.964). By using conventional search methods on the raw GC–MS data, this compound would have been impossible to reliably identify.


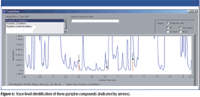
Figure 6
In addition to observing target compounds, the software was then used to determine the identity of an unknown compound that was coeluted with the target compound diethyl pyrazine. The appropriate area of the TIC is enlarged in Figure 8, showing multiple compounds eluted within the single peak. The selected unknown is represented by the symbol "U" and diethyl pyrazine represented by the symbol "T2." The relative heights of the HPlot bars show a significantly higher concentration for the coeluted compound U over the target compound T2. The spectrum for U (Figure 9) was extracted and searched in NIST, as mentioned earlier (Figure 10). A strong match was found, therefore, the compound was identified as dimethyl styrene with high confidence.

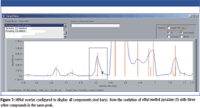
Figure 7
Conclusions
The analysis of food products using a microchamber with TD-GC–TOF-MS generates a comprehensive yet complex TIC profile. The identification of trace-level targets within this convoluted matrix would not be possible using conventional library searching techniques.


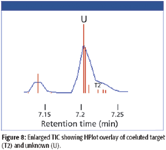
Figure 8
In this application, the spectral deconvolution and advanced chemometrics of the novel software have resulted in the successful identification of trace-level pyrazines with strong confidence values. This is a clear demonstration of the intensive data-mining capabilities afforded by new software tools. In addition, the software permits the identification of unknown compounds where necessary.


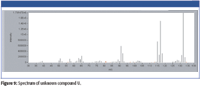
Figure 9
With the advent of product quality and safety regulations requiring the monitoring of specific VOCs, and when faced with the time constraints found in a busy production environment, the use of such software will translate into increased productivity, saving time and ultimately cost in the VOC analysis of a product.


Figure 10
Gareth M. Roberts is with ALMSCO International, Ltd., Llantrisant, UK.
References
(1) Markes International TDTS Note 52: The use of TD-GC/MS in flavour and fragrance profiling and food analysis (2009).
(2) Markes International TDTS Note 68: Using Markes emission screening technology to simplify compliance with the latest construction product regulations (2010).
(3) Markes International TDTS Note 90: Automatic detection of trace target compounds in complex chemical emission profiles from products and materials (2010)
















High-Speed Laser MS for Precise, Prep-Free Environmental Particle Tracking
April 21st 2025Scientists at Oak Ridge National Laboratory have demonstrated that a fast, laser-based mass spectrometry method—LA-ICP-TOF-MS—can accurately detect and identify airborne environmental particles, including toxic metal particles like ruthenium, without the need for complex sample preparation. The work offers a breakthrough in rapid, high-resolution analysis of environmental pollutants.


The Fundamental Role of Advanced Hyphenated Techniques in Lithium-Ion Battery Research
December 4th 2024Spectroscopy spoke with Uwe Karst, a full professor at the University of Münster in the Institute of Inorganic and Analytical Chemistry, to discuss his research on hyphenated analytical techniques in battery research.

Mass Spectrometry for Forensic Analysis: An Interview with Glen Jackson
November 27th 2024As part of “The Future of Forensic Analysis” content series, Spectroscopy sat down with Glen P. Jackson of West Virginia University to talk about the historical development of mass spectrometry in forensic analysis.

Detecting Cancer Biomarkers in Canines: An Interview with Landulfo Silveira Jr.
November 5th 2024Spectroscopy sat down with Landulfo Silveira Jr. of Universidade Anhembi Morumbi-UAM and Center for Innovation, Technology and Education-CITÉ (São Paulo, Brazil) to talk about his team’s latest research using Raman spectroscopy to detect biomarkers of cancer in canine sera.


